

| Current | v9 | v8 | v7 | v6 | v5 | v4 | v3 | v2 | v1 | All | About |
Implementing the Decoder
The implementation of the decoder involves taking the encoded form and converting it back into the raw form. This must all be done using assembly instructions that will execute natively on the target machine after an exploit has succeeded and it must also use only those instructions that fall within the valid character set. To accomplish this, it makes sense to figure out what instructions are available out of the valid character set. To do that, it's as simple as generating all of the permutations of the valid characters in both the first and second byte positions. This provides a pretty good idea of what's available. The end-result of such a process is a list of about 105 unique instructions (independent of operand types). Of those instructions the most interesting are listed below:
add sub imul inc cmp jcc pusha push pop and or xor
Some very useful instructions are available, such as add, xor, push, pop, and a few jcc's. While there's an obvious lack of the traditional mov instruction, it can be made up for through a series of push and pop instructions, if needed. With the set of valid instructions identified, it's possible to begin implementing the decoder. Most decoders will involve three implementation phases. The first phase is used to determine the base address of the decoder stub using a geteip technique. Following that, the encoded data must be transformed from its character-safe form to the form that it will actually execute from. Finally, the decoder must transfer control into the decoded data so that the actual payload can begin executing. These three steps will be described in the following sections.
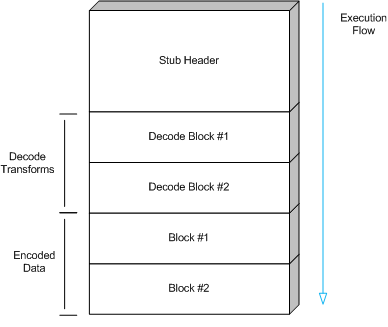
In order to better understand the following sections, it's important
to describe the general approach that is going to be taken to
implement the decoder. Figure ![[*]](images/html/crossref.png) describes the
general structure of the decoder. The stub header is used to
prepare the necessary state for the decode transforms. The
transforms themselves take the encoded data, as a series of four
byte blocks, and translate it using the process described in section
. Finally, execution falls through to the decoded
data that is stored in place of the encoded data.
describes the
general structure of the decoder. The stub header is used to
prepare the necessary state for the decode transforms. The
transforms themselves take the encoded data, as a series of four
byte blocks, and translate it using the process described in section
. Finally, execution falls through to the decoded
data that is stored in place of the encoded data.
Subsections
- Determining the Stub's Base Address
- Transforming the Encoded Data
- Transferring Control to the Decoded Data