

| Current | v9 | v8 | v7 | v6 | v5 | v4 | v3 | v2 | v1 | All | About |
Basic Block Tier
Once the complete set of data flow paths are identified at the instruction tier for a given procedure, the next step is to generalize data flow information to the basic block tier. At the basic block tier, instruction data flow paths should be generalized to show path-sensitive data flow interactions between basic blocks rather than instructions. This level of generalization reduces the amount of information needed to represent data flow paths. For example, there are many cases where data will be passed between multiple instructions within the same basic block. Using basic block tier generalization, those individual operations can be generalized and represented as a single basic block. The generalized basic block data flow paths can then be persisted for subsequent use when determining reachability in much the same fashion that was used at the instruction tier.
Since the instruction tier's data flow information has been fractured and parameters passed at call sites have been tied to phi functions, an approach must be defined to preserve this information at the basic block tier during generalization. An easy way of preserving this information is to define the formal parameters which represent input and output parameters as being contained within distinct pseudo blocks. For example, the phi functions representing formal input parameters can exist within a formal entry pseudo block. Likewise, the phi functions representing formal output parameters can exist within a formal exit pseudo block. Both pseudo blocks can then be tied to the procedure associated with the formal parameters. Defining the underlying instruction tier phi functions in this way makes it trivial to retain information that will be needed to define context-sensitive interprocedural data flow at less-specific generalization tiers. Like the instruction tier, it is possible to dynamically link data passed to a pseudo block in a caller's context to subsequent uses in a callee's context. Figure 5 shows the general form that basic block data flow paths may take.
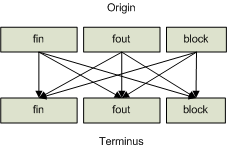
The act of generalizing instruction data flow paths means that two or more distinct instruction data flow paths may produce the same basic block data flow path. When this occurs, only one basic block data flow path should be defined since it will effectively capture the information conveyed by the set of distinct instruction data flow paths. Each corresponding instruction data flow path should still be associated with a single basic block data flow path. This association makes it possible to show the set of instruction data flow paths that have been generalized by a specific basic block data flow path. The association can be persisted in a normalized database by creating a one-to-many link table between basic block and instruction data flow paths. Figure 6 provides an example of what would happen when generalizing the instruction data flow paths described in figure 4.
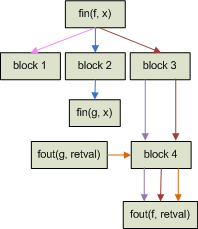 |