

| Current | v9 | v8 | v7 | v6 | v5 | v4 | v3 | v2 | v1 | All | About |
Abstract Tiers
Abstract tiers represent the most general view of the data flow behaviors of an application. The data flow behavior is modeled with respect to abstract software elements, such as a component, rather than concrete software elements, such as a module or a type. For this example, it is assumed that the PQE algorithm begins by modeling data flow behaviors between conceptual components in a web application. The web application is composed of two manually defined abstract components, a Web Client and a Web Service. These two components both rely on external libraries, as represented by the Undefined component, which are outside of the scope of the application itself. When starting at the abstract tier, all abstract data flow paths must be considered as potential data flow paths. The component tier data flow graph for this application is shown in figure 14.
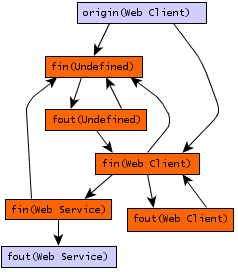 |
Using the data flow graph shown in figure 14, PQE uses the
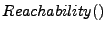 algorithm to determine data flow paths between a formal output parameter in the Undefined component and a formal input parameter in the Undefined component. At this generalization tier, there are many different paths that can be taken between these two components. This effectively results in the qualification of nearly all of the assembly tier data flow paths. These data flow paths are used to represent the data flow graph at the assembly tier.
algorithm to determine data flow paths between a formal output parameter in the Undefined component and a formal input parameter in the Undefined component. At this generalization tier, there are many different paths that can be taken between these two components. This effectively results in the qualification of nearly all of the assembly tier data flow paths. These data flow paths are used to represent the data flow graph at the assembly tier.
In this example, PQE offers no improvements at abstract tiers because it is a requirement that all abstract data flow information be represented. Since the amount of information required to represent abstract data flow is minimal, this is not seen as a deficiency. Furthermore, for this particular example, nearly all component data flow paths are found to be involved in reachable paths. At worst, this is indicative that for small applications, it may not be necessary to start the algorithm by looking at abstract data flow information. Instead, one might immediately progress to the module or data type tiers.